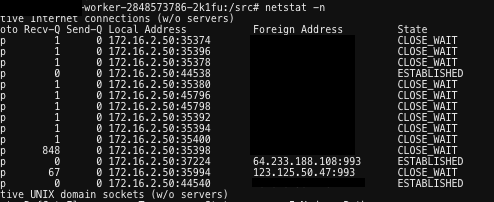
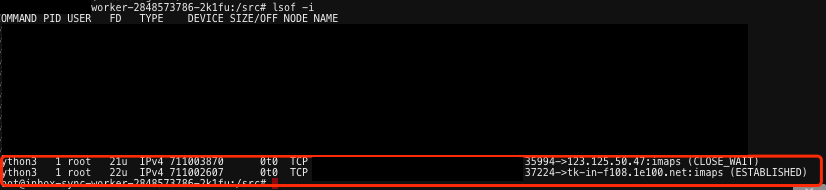
- 在个人的私有项目实践中,使用了腾讯云的 cmongo (base on mongodb v3.2),在端详日志的时候,发现偶尔会出现下述问题:
- Cursor not found (namespace: ‘db_name.collection_name’, id: cursor_id).
- 频率大概是 3次/天
依赖信息
mongodb (cmongo: v3.2), 在腾讯云上以副本集方式部署
python 模拟业务代码一份
问题分析
google 关键词
- 关键词: mongodb cursor not found
- link: MongoDB - Error: getMore command failed: Cursor not found
- 概要: 大部分描述是由于 timeout 导致的,timeout 默认时间大概是 10 分钟
- 现象分析: 由于模拟的业务代码里是 delete 操作而且从数据量上分析,要 cursor 超过 10 分钟的概率非常小,暂时摒弃从 timeout 上分析的路径
- 附上一个 (v 3.6+) 相关 Jira 链接 Session cache refresh can erroneously kill cursors that are still in use,大概讲了 cache refresh 导致 cursor 被清掉了, 这个挺靠谱的
下载源码 mongodb (v3.2) 分析
- 搜索 “cursor not found” 关键字
- 找到对应的源码文件在 cluster_cursor_manager.cpp 中,由 “cursorNotFoundStatus” 定义。这个错误可以由 killCursor,detachCursor_inlock,checkOutCursor等函数抛出,从该源文件看,该类型错误可能由 集群关闭 / cursor没有注册成功 / cursor处于 kill pending(如: timeout) 等原因状态导致
- 由于腾讯云的监控显示在 cursor not found 出现的时候集群状态是正常的, 所以由于集群关闭导致的可能性不大
- 从 cluster_cursor_manager.cpp 中可以看出 cursor 是由 cursor_manager 管理的, 在 cursor_manager.cpp 文件中可以找到 timeoutCursors,eraseCursor,invalidateAll 等相关方法
全局搜索与 cursor_manager 相关的 invalidateAll 方法,可以在 index_catalog.cpp 中找到相关的代码
1
2
3
4
5
6
7
8
9
10Status IndexCatalog::_dropIndex(OperationContext* txn, IndexCatalogEntry* entry) {
// ...
// TODO only kill cursors that are actually using the index rather than everything on this
// collection.
if (entry->isReady(txn)) {
_collection->getCursorManager()->invalidateAll(
false, str::stream() << "index '" << indexName << "' dropped");
}
// ...
}由上述代码以及注释可以发现如果删除一个 collection 的 index 的话,会同时 invalidateAll cursors,可以尝试通过该手段去验证是否会报 cursor not found 错误
- 搜索 “cursor not found” 关键字
复现方法
- 写一段代码获取某 collection 的 curosr, 迭代该 cursor, 并在每次迭代中 sleep 1 秒
- 在另外的 session 中开一个 mongo shell,并在其中创建然后删除该 collection 下的 index
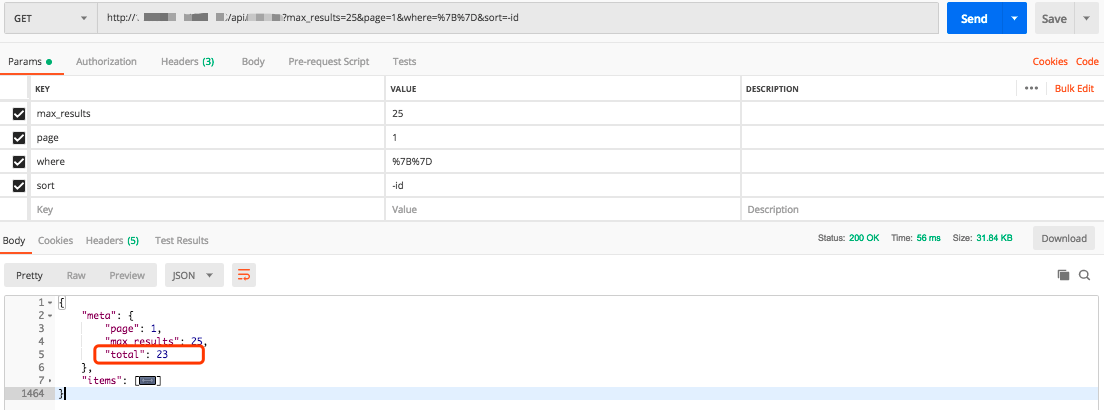
- 可以发现我们的模拟代码会抛出 cursor not found 的错误

总结
- 虽然能够复现出 cursor not found 的问题,但是跟实际上的日志错误还是有一定差别的,实际的日志错误是带有 namespace 等信息的,但是在我们的复现路径中并不能看见如此信息。
- 从代码实现以及注释上看,导致实际的 cursor not found 的原因极可能由于 curosr manager 对 cursor 的 “粗粒度” 管理导致的
- 至于最后的解决方案: 可以通过 try catch retry 的方式去对实际业务代码进行相对应的改造修复